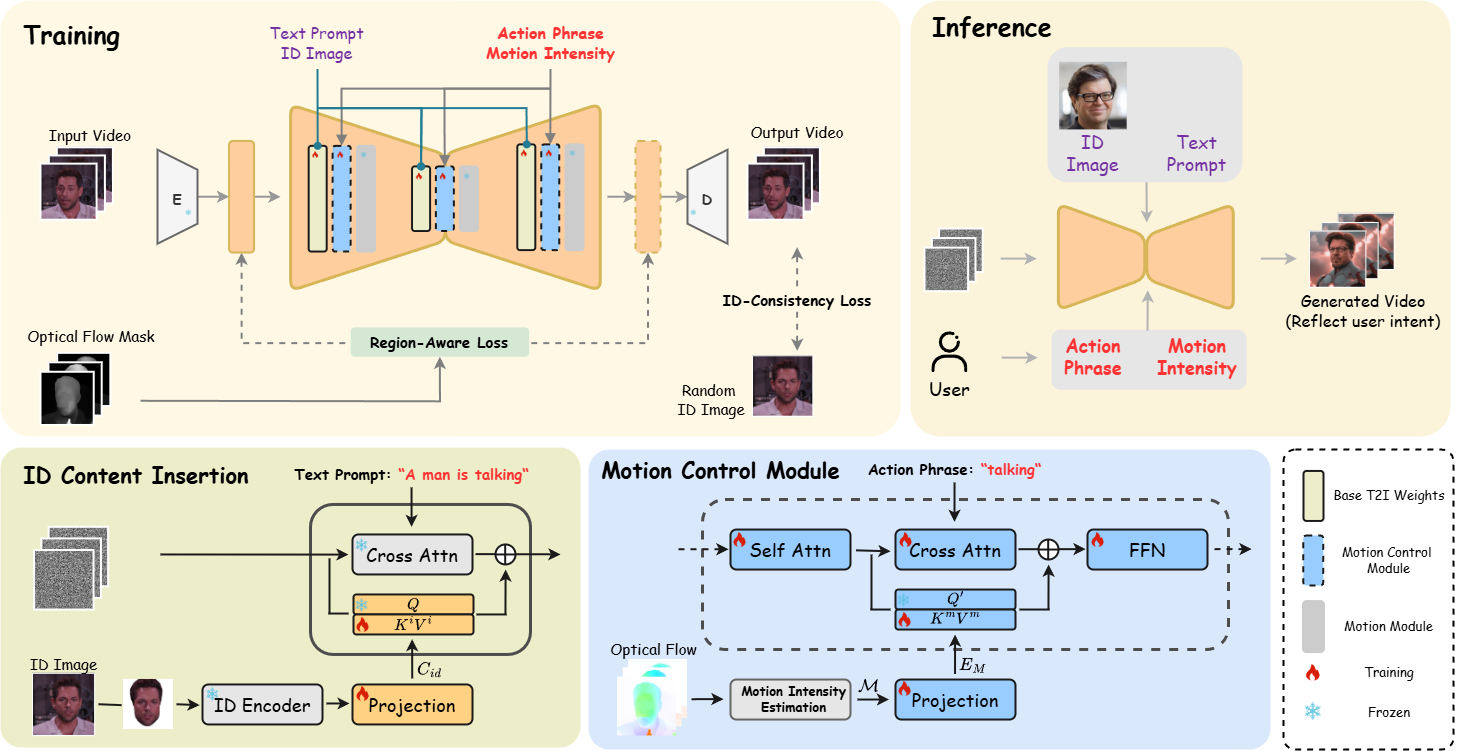
To build the Human-Motion Dataset, a multi-step pipeline was developed to ensure the collection of high-quality video clips:
1. Video Sources: Our data sources comprise video clips from diverse origins, including
VFHQ, CelebV-Text,
CelebV-HQ, AAHQ, and a private dataset, Sing Videos.
2. Filtering Process: To maintain data quality, a multi-step filtering process was applied:
-
Visual Quality Check: We used CLIP Image Quality Assessment (CLIP-IQA) to evaluate visual quality by sampling one frame per clip, discarding videos with frames of low quality.
-
Resolution Filter: Videos with resolutions below 512 pixels were removed to uphold visual standards.
-
Text Overlay Detection: EasyOCR was used to detect excessive subtitles or text overlays, filtering out obstructed frames.
-
Face Detection: Videos containing multiple faces or low face detection confidence were discarded to ensure each video contains a single, clearly detectable person.
3. Captioning: To enrich motion-related data, we utilized MiniGPT to automatically generate two types of captions for each video:
-
Overall Descriptions (𝒫): General summaries of the video content.
-
Action Phrases (𝒜): Detailed annotations of facial and body movements, serving as action phrases 𝒜 in our framework.
4. Optical Flow Estimation: We use the RAFT model on video frames to compute optical flow, determining motion intensity for training and optimizing the loss function.
5. Motion Intensity Resampling: We resampled videos to balance the dataset, ensuring an even distribution of motion intensity values within the range of 0 to 20.
6. Dataset Summary: The Human-Motion dataset consists of 106,292 video clips. Each clip was rigorously filtered and re-annotated to ensure high-quality identity and motion information across diverse formats, resolutions, and styles.








































.gif)
.gif)
.gif)








